GPGPUのお勉強
GPUとしての動作に最適化されたGK104。NVIDIAはGPGPU向けに「もう1つのKepler」を準備中
グラフィックス業界関係者の間にある,「GPUの性能は数学」(ピーク演算性能は「GPUコアの演算能力×コア数×動作クロック」で求められる。それ以上でも以下でもない)という統一見解は,Keplerアーキテクチャを採用したNVIDIAの新世代GPU「GeForce GTX 680」(以下,GTX 680)にも当てはまる。
NVIDIAでGPUアーキテクチャの開発を指揮するJonah Alben(ヨナ・アルベン)上級副社長は,CUDA Coreの構成やSFU(Special Function Unit,超越関数ユニット)について,「Keplerアーキテクチャでは,より多くのCUDA Coreを効率よく動作させられるよう,半導体設計そのものから見直しを図った」と説明しているが,そのカギを握るのは,Tesla~Fermi世代でNVIDIAが採用してきた「倍速クロック」仕様の廃止だ(表1)。
NVIDIAは,GeForce 200~500世代で,CUDA Coreをコアクロック(エンジンクロック)の倍速で動作させることにより,少ない演算器でも高い性能を発揮させるようなアプローチをとってきた。ただこれは,「限りあるトランジスタ数で最大限の性能を引き出すためだったが,このアプローチだと,回路設計がやや複雑になり,消費電力も引き上げる結果になってしまった」(Alben氏)。
そこでNVIDIAは,Keplerアーキテクチャで28nmプロセス技術を採用したことを機に,倍速クロックを止めて消費電力の問題を解決し,合わせてSM(Streaming Multiprocessor)の構成を見直すことで,より多くのCUDA Coreを搭載できるようにした。このあたりはGTX 680発表時の記事でお伝えしているとおりだ。
Alben氏はこの点について「シングルクロック化にあたって,Fermiアーキテクチャ時代と同じ性能を実現するため,回路規模を1.8倍に増やす必要が生じた」と振り返っている。
この発言は要するに,「倍速クロック仕様と同じ性能を等速クロック仕様で実現しようとすると,回路規模は単純計算なら2倍必要になるが,倍速クロック動作に必要なクロック同期回路(ラッチ回路)の数が半分になる。また,倍速クロック動作を実現するために二重化していたLoad/Store Unit(ロード/ストアユニット)を,そうしなくてよくなるので,回路規模は1.8倍で済む」という意味だ。
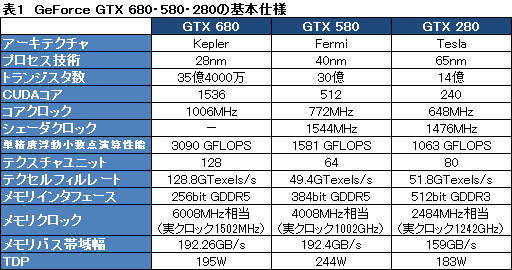
すでにお伝えしているように,GTX 680で搭載されるCUDA Coreの数は合計で1536基に達している。「GeForce GTX 580」(以下,GTX 580)比で3倍だ。倍速クロック仕様となるGTX 580だと,シェーダクロックは1544MHzなのに対し,GTX 680では1006MHzなので,動作クロック,ひいてはCUDA Coreあたりの処理能力がGTX 580比約65%にまで低下している計算になるが,それでも物量の多さによって,単精度浮動小数点演算性能は1581 GFLOPSのGTX 580に対し,GTX 680では3090 GFLOPSへと向上している。
また,シェーダクロックではなく,コアクロックが向上したことは,CUDA Core以外におけるGPU機能の高性能化にも大きく貢献している。さらに,今日(こんにち)のGPUにおいて大きな面積を占めるL2キャッシュ容量を,GTX 580の768KBからGTX 680で512KBへと削減してきたことで,SFUやテクスチャユニットの数を増やすための余裕が生まれたことも指摘しておくべきだろう。
これにより,GTX 680の「GK104」コアでは,GTX 580からわずか5億トランジスタが増えただけで,GTX 580比で2倍の単精度浮動小数点演算性能を実現できているのだ。このあたりは4Gamerの連載「西川善司の3Dゲームエクスタシー」でも述べられているため,興味のある人は合わせて参照してもらえればと思うが,ともあれ,GTX 680におけるGTX 580からの強化ポイントをまとめたものが表2,3になる。
Alben氏は,GTX 680で採用されたGK104コアを「GPUに最適化されたKeplerアーキテクチャだ」と位置づけている。
まだ記憶に新しいという読者も多いと思うが,NVIDIAはTesla~Fermi世代のGPU開発で,GPUコンピューティング(=GPGPU)性能の向上とそれに伴う機能拡張を優先してきた。別の言い方をすると,Tesla~Fermi世代のGPUでは,限りあるトランジスタ数の少なくない量を,GPUコンピューティング専用の回路が占めていたのだ。
それに対し,GK104では,3Dアプリケーションを前にしたときの純然たるGPU性能の向上を最優先にした半導体設計がなされている。それにより,「GF114」コアの「GeForce GTX 560 Ti」よりも小さな294mm2というダイサイズで,新世代のシングルGPU最上位モデルに相応しい3Dグラフィックス性能を獲得してきたというわけなのである。
一方,2011年12月に中国・北京市で開催された「GTC Asia 2012」において,NVIDIAを率いるJen-Hsun Huang(ジェンスン・フアン)CEOは「GPU開発において,『最先端プロセスで,できる限りのトランジスタを集積し,性能を向上させていく』というスタンスに変わりはない」と述べ,GPUコンピューティング向けに,より多くのトランジスタを集積させたチップの投入を示唆していた。
そしてこれは,HPC(High Performance Computing)関係者が,「(2012年における世界最速のスーパーコンピュータとなると目される)Crayの『Titan XK6』が,GPUコンピューティング向けのGPU『Kepler II』を採用する」と述べていることと合致する。
つまり,Kepler IIと呼ばれるGPUコンピューティング向けチップでは,GK104よりも多くのCUDA Coreが搭載され,HPC向けの最適化が行われるということだ。NVIDIAに近い業界関係者は,「いわゆるグラフィックスチップとしてのKepler IIは,(GK104と比べて)性能や電力効率が落ちるものになりそうだ」と,筆者の取材に対して述べている。
繰り返しになるが,NVIDIAがKeplerで目指したのは「消費電力あたりの性能」の大幅な引き上げだ。依然として安定した供給が見込めないTSMCの28nmプロセスで物理的に大きなチップを製造することはリスクが大きすぎるというのもあるので,新しいGPUアーキテクチャを導入するにあたり,NVIDIAが,より多くの出荷量を見込める3Dグラフィックス処理向けGPU(=GeForce)へ最適化する戦略に出たことは,妥当と述べていいだろう。
もう1つ注目しておきたいのは,NVIDIAの公開しているGPUコアロードマップが,浮動小数点演算性能の単純比較ではなく,
になっていることだ。
今日(こんにち)のGPUが直面している課題の1つに,「コア数を増やしてピーク性能を引き上げても,実際のアプリケーションではその性能を活かし切れない」というジレンマがある。最新の3Dゲームタイトルでアンチエイリアシングなどの負荷を大きくしても,GPUのリソースを100%使い切るというケースは滅多にない。
NVIDIAがGeForce GTX 600シリーズで導入した自動クロックアップ機能「GPU Boost」は,まさにこの問題へ対処するものだ。消費電力に余裕があるとき,その余裕を自動クロックアップ分に振り分けるというアプローチによって,消費電力あたりの「持続的」な性能を引き出しているというわけなのである。
同様のアプローチは,Intelの「Intel Turbo Boost Technology」やAMDの「AMD OverDrive」「AMD PowerTune Technology」にも見られるが,実際,マルチコア化の進む現在の半導体業界では一般的な手法だ。
その背景には,「マルチコア化が進んでも,命令の依存関係や,逐次実行するしかない処理がボトルネックとなり,コア数の増加分だけリニアに並列処理性能を上げるのは難しい」という「アムダールの法則」の存在がある。
GTX 680のベンチマーク結果を見ても,そのことは想像できるだろう。GTX 580と比べて2倍のピーク演算性能を実現しているにもかかわらず,GTX 680の3D性能は,GPU Boostの助けを借りても最大50%程度の性能向上率に留まっていることからは,GPUコアの数を増やしつつ,効率的な処理を行っていくことの難しさが伝わってくる。
Alben氏は,「GPUコア数を増やしつつ,その処理効率を引き上げるためにはアーキテクチャに大きくメスを入れる必要性が出てくる」としつつ,「(コンシューマ向け製品となるGPUでは)ゲームタイトルなどの互換性を最優先すると,現在のタイミングでWarpを拡張したり,制御するスレッド数を大幅に変更したりすることは難しい」とも述べていたが,これは示唆に富んだ発言だ。
というのも,GPUコンピューティング向けの製品における,持続的性能を阻害する要素自体は「演算に利用する大量のデータを転送するのに要するレイテンシ」や「複数ノード間における通信の待ち時間」などになり,ゲームタイトルでのそれとは大きく異なるからである。持続的性能を向上させるために,Kepler(=GeForce GTX 600シリーズ)のような自動クロックアップといった手法を採るより,キャッシュ階層の見直しやアーキテクチャの拡張を優先したほうが,効率はずっといい。
NVIDIAのCTOであるSteve Scott氏は筆者の取材に対し,「HPC用途であれば,高性能化のためにアプリケーションを再構築することもいとわないユーザーは多い」と述べていたが,以上の状況証拠からするに,3Dグラフィックス向けのGeForceと,GPUコンピューティング向けのTeslaは,ベースとなるGPUアーキテクチャを共有しつつ,それぞれ別の進化を遂げる可能性が出てきたといえるだろう。
なお,GPUコンピューティング向けに最適化されるKepler IIがGeForceに転用される可能性は高いとも言われている。Keplerアーキテクチャの最高峰となるKepler IIがどのようなラインナップで展開されるのか,興味は尽きない。
NVIDIAでGPUアーキテクチャの開発を指揮するJonah Alben(ヨナ・アルベン)上級副社長は,CUDA Coreの構成やSFU(Special Function Unit,超越関数ユニット)について,「Keplerアーキテクチャでは,より多くのCUDA Coreを効率よく動作させられるよう,半導体設計そのものから見直しを図った」と説明しているが,そのカギを握るのは,Tesla~Fermi世代でNVIDIAが採用してきた「倍速クロック」仕様の廃止だ(表1)。
 |
NVIDIAは,GeForce 200~500世代で,CUDA Coreをコアクロック(エンジンクロック)の倍速で動作させることにより,少ない演算器でも高い性能を発揮させるようなアプローチをとってきた。ただこれは,「限りあるトランジスタ数で最大限の性能を引き出すためだったが,このアプローチだと,回路設計がやや複雑になり,消費電力も引き上げる結果になってしまった」(Alben氏)。
そこでNVIDIAは,Keplerアーキテクチャで28nmプロセス技術を採用したことを機に,倍速クロックを止めて消費電力の問題を解決し,合わせてSM(Streaming Multiprocessor)の構成を見直すことで,より多くのCUDA Coreを搭載できるようにした。このあたりはGTX 680発表時の記事でお伝えしているとおりだ。
Alben氏はこの点について「シングルクロック化にあたって,Fermiアーキテクチャ時代と同じ性能を実現するため,回路規模を1.8倍に増やす必要が生じた」と振り返っている。
 |
この発言は要するに,「倍速クロック仕様と同じ性能を等速クロック仕様で実現しようとすると,回路規模は単純計算なら2倍必要になるが,倍速クロック動作に必要なクロック同期回路(ラッチ回路)の数が半分になる。また,倍速クロック動作を実現するために二重化していたLoad/Store Unit(ロード/ストアユニット)を,そうしなくてよくなるので,回路規模は1.8倍で済む」という意味だ。
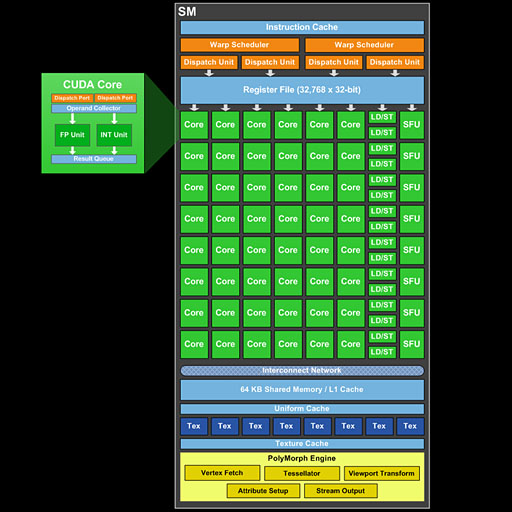 |
| 倍速クロックを採用するFermi世代のGPUでは,コアクロックと同期するLoad/Store Unit(※図中「LD/ST」)が二重化されていた |
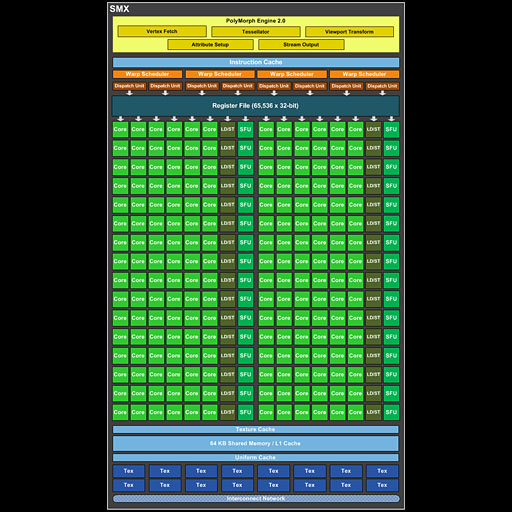 |
| シングルクロック化を果たしたKeplerアーキテクチャでは,Load/Store Unit数が少なくなった一方,SFUは強化され,それが演算性能の引き上げにつながっている |
すでにお伝えしているように,GTX 680で搭載されるCUDA Coreの数は合計で1536基に達している。「GeForce GTX 580」(以下,GTX 580)比で3倍だ。倍速クロック仕様となるGTX 580だと,シェーダクロックは1544MHzなのに対し,GTX 680では1006MHzなので,動作クロック,ひいてはCUDA Coreあたりの処理能力がGTX 580比約65%にまで低下している計算になるが,それでも物量の多さによって,単精度浮動小数点演算性能は1581 GFLOPSのGTX 580に対し,GTX 680では3090 GFLOPSへと向上している。
また,シェーダクロックではなく,コアクロックが向上したことは,CUDA Core以外におけるGPU機能の高性能化にも大きく貢献している。さらに,今日(こんにち)のGPUにおいて大きな面積を占めるL2キャッシュ容量を,GTX 580の768KBからGTX 680で512KBへと削減してきたことで,SFUやテクスチャユニットの数を増やすための余裕が生まれたことも指摘しておくべきだろう。
 |
 |
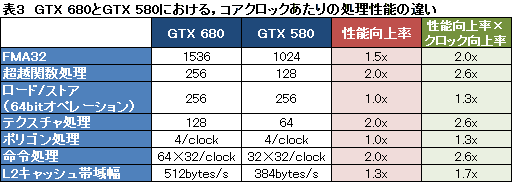
これにより,GTX 680の「GK104」コアでは,GTX 580からわずか5億トランジスタが増えただけで,GTX 580比で2倍の単精度浮動小数点演算性能を実現できているのだ。このあたりは4Gamerの連載「西川善司の3Dゲームエクスタシー」でも述べられているため,興味のある人は合わせて参照してもらえればと思うが,ともあれ,GTX 680におけるGTX 580からの強化ポイントをまとめたものが表2,3になる。
 |
 |
GPUとしての動作に最適化されたGK104
GPGPU処理向けには「Kepler II」を用意
Alben氏は,GTX 680で採用されたGK104コアを「GPUに最適化されたKeplerアーキテクチャだ」と位置づけている。
まだ記憶に新しいという読者も多いと思うが,NVIDIAはTesla~Fermi世代のGPU開発で,GPUコンピューティング(=GPGPU)性能の向上とそれに伴う機能拡張を優先してきた。別の言い方をすると,Tesla~Fermi世代のGPUでは,限りあるトランジスタ数の少なくない量を,GPUコンピューティング専用の回路が占めていたのだ。
それに対し,GK104では,3Dアプリケーションを前にしたときの純然たるGPU性能の向上を最優先にした半導体設計がなされている。それにより,「GF114」コアの「GeForce GTX 560 Ti」よりも小さな294mm2というダイサイズで,新世代のシングルGPU最上位モデルに相応しい3Dグラフィックス性能を獲得してきたというわけなのである。
 |
そしてこれは,HPC(High Performance Computing)関係者が,「(2012年における世界最速のスーパーコンピュータとなると目される)Crayの『Titan XK6』が,GPUコンピューティング向けのGPU『Kepler II』を採用する」と述べていることと合致する。
つまり,Kepler IIと呼ばれるGPUコンピューティング向けチップでは,GK104よりも多くのCUDA Coreが搭載され,HPC向けの最適化が行われるということだ。NVIDIAに近い業界関係者は,「いわゆるグラフィックスチップとしてのKepler IIは,(GK104と比べて)性能や電力効率が落ちるものになりそうだ」と,筆者の取材に対して述べている。
繰り返しになるが,NVIDIAがKeplerで目指したのは「消費電力あたりの性能」の大幅な引き上げだ。依然として安定した供給が見込めないTSMCの28nmプロセスで物理的に大きなチップを製造することはリスクが大きすぎるというのもあるので,新しいGPUアーキテクチャを導入するにあたり,NVIDIAが,より多くの出荷量を見込める3Dグラフィックス処理向けGPU(=GeForce)へ最適化する戦略に出たことは,妥当と述べていいだろう。
もう1つ注目しておきたいのは,NVIDIAの公開しているGPUコアロードマップが,浮動小数点演算性能の単純比較ではなく,
- 消費電力あたりの「持続的」浮動小数点演算性能
になっていることだ。
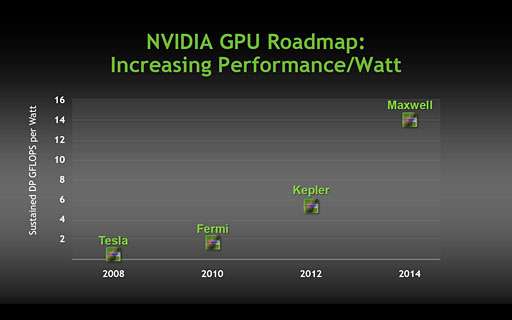 |
今日(こんにち)のGPUが直面している課題の1つに,「コア数を増やしてピーク性能を引き上げても,実際のアプリケーションではその性能を活かし切れない」というジレンマがある。最新の3Dゲームタイトルでアンチエイリアシングなどの負荷を大きくしても,GPUのリソースを100%使い切るというケースは滅多にない。
NVIDIAがGeForce GTX 600シリーズで導入した自動クロックアップ機能「GPU Boost」は,まさにこの問題へ対処するものだ。消費電力に余裕があるとき,その余裕を自動クロックアップ分に振り分けるというアプローチによって,消費電力あたりの「持続的」な性能を引き出しているというわけなのである。
同様のアプローチは,Intelの「Intel Turbo Boost Technology」やAMDの「AMD OverDrive」「AMD PowerTune Technology」にも見られるが,実際,マルチコア化の進む現在の半導体業界では一般的な手法だ。
その背景には,「マルチコア化が進んでも,命令の依存関係や,逐次実行するしかない処理がボトルネックとなり,コア数の増加分だけリニアに並列処理性能を上げるのは難しい」という「アムダールの法則」の存在がある。
GTX 680のベンチマーク結果を見ても,そのことは想像できるだろう。GTX 580と比べて2倍のピーク演算性能を実現しているにもかかわらず,GTX 680の3D性能は,GPU Boostの助けを借りても最大50%程度の性能向上率に留まっていることからは,GPUコアの数を増やしつつ,効率的な処理を行っていくことの難しさが伝わってくる。
Alben氏は,「GPUコア数を増やしつつ,その処理効率を引き上げるためにはアーキテクチャに大きくメスを入れる必要性が出てくる」としつつ,「(コンシューマ向け製品となるGPUでは)ゲームタイトルなどの互換性を最優先すると,現在のタイミングでWarpを拡張したり,制御するスレッド数を大幅に変更したりすることは難しい」とも述べていたが,これは示唆に富んだ発言だ。
というのも,GPUコンピューティング向けの製品における,持続的性能を阻害する要素自体は「演算に利用する大量のデータを転送するのに要するレイテンシ」や「複数ノード間における通信の待ち時間」などになり,ゲームタイトルでのそれとは大きく異なるからである。持続的性能を向上させるために,Kepler(=GeForce GTX 600シリーズ)のような自動クロックアップといった手法を採るより,キャッシュ階層の見直しやアーキテクチャの拡張を優先したほうが,効率はずっといい。
NVIDIAのCTOであるSteve Scott氏は筆者の取材に対し,「HPC用途であれば,高性能化のためにアプリケーションを再構築することもいとわないユーザーは多い」と述べていたが,以上の状況証拠からするに,3Dグラフィックス向けのGeForceと,GPUコンピューティング向けのTeslaは,ベースとなるGPUアーキテクチャを共有しつつ,それぞれ別の進化を遂げる可能性が出てきたといえるだろう。
なお,GPUコンピューティング向けに最適化されるKepler IIがGeForceに転用される可能性は高いとも言われている。Keplerアーキテクチャの最高峰となるKepler IIがどのようなラインナップで展開されるのか,興味は尽きない。