GRID2.0 とは何か?

NVIDIAはデータセンタ側のサーバに搭載するGPUに力を入れている。
「GRID 2.0」と呼ぶリモートグラフィックス機能は、サーバ側のGPUを仮想化して多数のグラフィックユーザをサポートする。NVIDIAは、この8月にGrid 2.0用のGPUとして「Tesla M60」と「Tesla M6」という製品を発表している。
今回はそれに続く巨大データセンタ向けの2種のGPU「Tesla M40」と「Tesla M4」を発表した。M60とM6はグラフィックス処理をサーバ側で行うためのGPUであるが、今回のM40とM4はディープラーニングやイメージ処理などの計算量の多い処理を、CPUからオフロードして、高速化し、消費電力を減らすことを目的としている。
Periscopeには毎日40年分のビデオがアップされ、Baiduには毎日60億のクエリが押し寄せ、その10%は音声認識を使うクエリである。また、YouTubeでは毎分300時間分のビデオが再生され、その50%はトランスコードを必要とするモバイルデバイスであるという。これらのサイトでは、大量のイメージや動画を処理するために、膨大な計算能力が必要になる。
これに対して、NVIDIAは次の図のようなGPU付きのデータセンタアーキテクチャを提案している。
NVIDIAの提案するTesla GPUを使うデータセンタの構造

ディープラーニングによる認識を行う場合、大量の学習データを使ってパラメータのチューニングを行うラーニングフェーズは長い時間(数時間から数週間のオーダ)がかかる。
このため、高速のGPUを搭載した左側のサーバを使う。一方、認識(推論:inference)を行う場合は、入力画像1枚だけを処理すれば良いので、計算量はそれほど多くは無く、短い時間で処理できる。
しかし、巨大データセンタでは大量の問い合わせが来るので、これらを並列に少ない消費電力で処理できる右側のサーバが適している。
左側の高速GPUとして、NVIDIAはTesla M40を推奨する。ディープラーニングの処理を行う「Caffe」を実行する場合、M40はCPUと比較して8倍高速であるという。また、巨大データセンタでの長時間連続稼働に耐えられる高い信頼性を持っているという。
一方、右側のスループットオリエンテッドな処理にはM4を推奨する。M4は電力効率に重点を置いたGPUであり、ディープラーニングを使う多数の認識を、高い電力効率で、並列に処理することができる。
また、M4は、画像のフィルタリングや変形、ビデオのトランスコードなどの大量の演算処理を行うという用途も狙っている。画像処理の定番ソフトであるPhotoshopはPC側での処理だけでなく、サーバ側で処理する形態のライセンスもあり、すでに、サーバ側での処理にも対応している。
そしてM4はロープロファイルのPCI基板であり、それに合わせてサーバを設計すれば、高い実装密度が得られるようになっている。
5000本のビデオストリームのリアルタイムのトランスコードを行う場合、これをCPUで行なうと5万台のサーバの60%の能力を必要とし、10.8MWの電力を必要とする。これを、GPUを搭載したサーバ使うことでCPUの5%、GPUの20%の能力で済み、1.2MWまで消費電力を減らせるという。
GRID2.0向けのM60、M6と今回発表されたM40、M4の諸元を比べると、次の表のようになる。
M60 M6 M40 M4
CUDAコア数 4096 1536 3072 1024
TFlops 7.4 不明 7.0 2.2
デバイスメモリ 16GB 8GB 12GB 4GB
消費電力 225~300W 75~100W 250W 50~75W
データセンタ向けGPUの諸元の比較
この比較を見ると、M40はM60よりクロックが高いと考えられ、CUDAコア数はM60の3/4であるが、TFlops値は5%低い程度である。これはスループットだけではなく、レーテンシにも、多少、配慮した結果と思われる。
PCやスマホはGPUを内蔵しているので、データセンタ側のGPU機能なんて不要と思われるかも知れないが、必ずしもはそうではない。
PCやスマホは、ユーザが自分でアプリをダウンロードしてインストールする必要がある。個人が使用する場合は仕方がないが、大きな企業では、各人がアプリを勝手にインストールすると環境がマシンごとに異なったりして、セキュリティアップデートが適切に行われているかなどを確認する手間が大変である。そして、セキュリティホールが出来てハッカーに攻撃されてデータ漏えいなどという事態になれば、目も当てられない。
これを、処理はすべてデータセンターの仮想化したサーバで行い、PCやスマホは、リモートのタッチパネルやキーボードなどの入力と表示だけを担当させることにすれば、アップデートやハッカー対策は、ずっと簡単になる。
また、PCやスマホに搭載されたGPUでは、アニメ映画の製作現場で使われるようなグラフィックス性能は持っていないし、ディープラーニングの学習には能力不足である。このような場合にはデータセンタのGPUを使う方が安上がりである。
NVIDIAは、M40を高い演算性能と大きなメモリを必要とするディープラーニングのラーニング処理などを行うGPUと位置付けている。
一方、M4は電力効率に重点を置いたGPUで、ラーニングでチューンされたモデルを使って認識処理(inferemce)を行うという使い方をするGPUという位置づけである。また、データセンタ経由でPhotoshopのようなソフトを用いた画像のフィルタリングや変形など大量の演算処理を行うという用途も狙っている。
このような理由から、企業では、処理をデータセンタに集中するという技術的な流れがあり、競争が激しく利益の薄いスマホ用SoCよりも、サーバ側で使われるGPUで先行し、利益を確保しようというのがNVIDIAの戦略であると考えられる。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
(部分引用)
NVIDIAはGPUリソースをリモートで利用するインフラストラクチャ「NVIDIA GRID」を進化させつつある。VDI(Virtual Desktop Infrastructure:仮想デスクトップ)では、サーバー上に仮想的に実現されたデスクトップ環境に、リモートアクセスすることで、あたかもローカルにあるリソースのように、サーバーリソースを使うことができるようにする。
利点は、サーバー側でにリソースを集約することで、リソースの有効活用、TCO(Total Cost of Ownership)の低減、データの安全などを実現しやすいこと。
VDI自体は以前から利用されているが、NVIDIA GRIDは、「CPUだけでなくGPUも仮想化」することで、GPUリソースも共有できるようにする。GPUで複数の仮想マシンを走らせるGPU仮想化を可能にし、サーバー側の1個のGPUを、「複数のリモートユーザーで共有できる」ようにする。「CPUエミュレーションでは得られないグラフィックスパフォーマンス」で、アプリケーションもそのままVDIで利用できるようにする。そのため、GRIDではバーチャルGPU「vGPU」を実現できるソフトウェアインフラストラクチャを提供している。
GRIDは現在、2世代目のバージョン GRID 2.0となっており、Maxwellアーキテクチャベースで最大8GBまでのメモリを使うことができる。
NVIDIAは右側のvGPUとGPUパススルーを提供している
シングルGPUでは8GBメモリで16ユーザー、デュアルGPUでは16GBメモリで32ユーザーをサポートする
NVIDIAはGRID 2.0のデモとして、「流体(Fluid)シミュレーション」を使ったデモを公開した。デモではサーバー側で走るCUDAシミュレーションとその結果のグラフィックスともに、クライアント側で、ローカルで走っているように扱うことができていた。しかし、このデモには、実は、ちょっとした仕掛けがあった。それは、流体シミュレーションのデモでは、1個のサーバー側GPUを1ユーザーで占有しており「GRIDの売りであるGPUリソースの共有化」は、なされていなかった。
◎限定されている現在のGRID 2.0でのGPUコンピューティング
実は、現在のGRID 2.0では、CUDAを使うことができるプロファイルを限定している。8GBプロファイル、つまり、GPUを1個まるごと1つの仮想マシンが占有するプロファイルでのみCUDAを利用できる。言い換えれば、他の仮想マシンと、「リソースの競合」が発生しないプロファイルでのみ、GPUコンピューティングが許可される。
現在のGRIDには複数のvGPUプロファイルがあり、1ユーザー当たりの割り当てのビデメモリ量と1GPU当たりのサポートユーザー数の関係で階層化されている。
512MBメモリのプロファイルなら最大16ユーザーのサポートが可能だ。8GBのメモリを16ユーザーで分割するからだ。しかし、8GBメモリのプロファイルでは、当然ながら1ユーザーしかサポートできない。現状では、CUDAやOpenCLを使うGPUコンピューティングは、8GBメモリの1ユーザープロファイルに限定されている。
GRIDのプロファイルとサポートする機能の関係
なぜ、GPUコンピューティングが、現在のGRIDの仮想化では制約されるのか。理由は簡単で、現在のNVIDIA GPUがプリエンプションをサポートしていないためだ。プリエンプション、つまり、実行中のタスクを中断して、別なタスクを実行、終了後に再び元のタスクの実行を再開することが、NVIDIA GPUではできない。プリエンプティブなコンテキストスイッチングのハードウェア支援機能を備えていないためだ。
現代的なCPUなら、実行中のタスクのコンテキストをプロセッサ外に保存(ストア)して、別なタスクのコンテキストをロードして実行、その後、元のタスクのコンテキストをプロセッサに復元(リストア)して実行を再開するコンテキストスイッチングが可能だ。
ここで言うコンテキストは、レジスタ内容やプログラムカウンタ値など、プロセッサの内部状態として保持しなければならない値だ。コンテキストスイッチによって、OSがタスクを自由にスケジュールすることが可能になり、割り込み処理もできる。
仮想化でも同様で、仮想マシンを切り替える際に、ゲストOSのコンテキストをいったんストアして、別のゲストOSのコンテキストをロードする必要がある。元のゲストOSに戻す時には、ストアしてあるコンテキストをリストアする。柔軟な仮想マシンの切り替えには、プリエンプティブなコンテキストスイッチングが必要となる。
しかし、プリエンプティティブなコンテキストスイッチングをサポートしていない現在のNVIDIA GPUでは、原則として、実行中のタスクが終わるまで、他のタスクに切り替えることができない。そのため、ある仮想マシン上で、実行に時間がかかるタスクをGPUが実行している間は、他の仮想マシンに切り替えられない。長時間のタスクが終わるまで、他の仮想マシン上のタスクは待たされる。
なぜ、GPUではプリエンプティブなコンテキストスイッチのサポートが遅れているのか。それは、GPUのコンテキストが膨大だからだ。GPUには膨大な演算プロセッサとレジスタがあり、汎用レジスタの待避だけでも大変だ。
また、GPUでは、タスクを論理ベクタ長のサイズwarpに分割して実行しており、各warp毎にプログラムカウンタや分岐のプレディケーションのためのマスクレジスタがある。GPUのコンテキストのサイズは膨大で、CPUのように簡単にはストア/リストアができない。そのため、NVIDIAではコンテキストスイッチをサポートして来なかった。また、AMD(ATI) GPUでも、最近までサポートできなかった。
グラフィックスタスクではプリエンプションが不要
こうした技術上の理由から、現在のNVIDIA GRIDでは、複数ユーザーの仮想マシンを1つのGPUで走らせる場合、制約が発生する。時間のかかるタスクの走る仮想マシンのために、共有するほかのユーザーのグラフィックスタスクの描画が遅くなるなどの問題が発生してしまう可能性がある。
CPUならコンテキストスイッチで切り替えることができるため問題にならないことが、GPUでは問題になる。これが、現在のNVIDIA GPUで、CUDAコンピューティングを使う場合に、「複数仮想マシンでの共有」ができない理由だ。
ところが、この問題は、グラフィックスアプリだけを使っている場合は、制約にならない。グラフィックスタスクでは、GPU側がプリエンプションに対応していなくても、複数ユーザーが仮想マシンでGPUを円滑に共有できる。なぜなら、グラフィックスでは、タスクをスイッチする際に、コンテキストを保存(ストア)する必要がないからだ。
グラフィックスでは、1画面を描画し終えた段階で、そのグラフィックスタスクのコンテキストは維持する必要がなくなる。言い換えれば、タスクは画面描画の小さな単位で独立している。そして、グラフィックスタスクは、必ず1フレームの描画時間の間に終える必要があり、一定のフレームレートを維持しようとすると、タスクの所要時間が短い。
そのため、グラフィックスタスクの場合は、複数のタスクを切り替える場合も、コンテキストをストアする必要がない。1つのグラフィックスタスクの画面描画が終わってから、別なグラフィックスタスクをロードすればいいからだ。ストア/リストアのコンテキストスイッチングが必要ない。コンテキストを保存する必要がないという意味で、「GPUはコンテキストスイッチングが高速」という言い方もをするGPU関係者までいる。
グラフィックスタスクでは、コンテキストの保存や復元が必要ない
グラフィックスタスクの場合は、制約は、描画のフレームレートと1画面の描画に必要となるGPUの処理時間の関係だけとなる。例えば、60fpsで描画する場合に、各ユーザーのタスクのGPUの処理時間がフレームレートの4分の1の時間で済むなら、4人のユーザーがGPUを共有しても60fpsで描画できることになる。そのため、グラフィックスタスクの負荷に応じて、プロファイルを使ってGPUを共有するユーザー数を調整すれば1フレームのサイクルに収まる。
GPUコンピューティングの仮想化ではプリエンプションが必須に
グラフィックスタスクは、このように短い処理であり、コンテキストのストア/リストアが不要である。そのため、GPUはコンテキストスイッチをハードウェアでサポートする必要がなかった。しかし、GPUコンピューティングのタスクとなると話が異なる。GPUコンピューティングでは、タスクによって処理時間が大きく異なる。1つのカーネルが延々と走っている場合がありうる。
そのため、GPUコンピューティングを絡めた瞬間に、GPUでの仮想化でもプリエンプティブなコンテキストスイッチングが必要となる。グラフィックスのような処理時間が一定のタスクばかりではないため、処理の長い仮想マシンを途中で止めて、他の仮想マシンをロード/ストアできなければ、円滑な仮想マシンの稼働ができない。
上がグラフィックスタスクのスイッチング、下がGPUコンピューティングタスクのスイッチング
こうした制約から、現在のNVIDIA GRID 2.0では、CUDAのサポートはコンテキストスイッチが必要のないプロファイルに限定している。仮想化でシェアして使えるのは、グラフィックスタスクという限定になっている。このことが、NVIDIAが現在のGRIDをVDI(Virtual Desktop Infrastructure)の進化形として位置づけている理由となっている。
しかし、分散型のコンピューティングの聖杯は、蛇口をひねると水が出るように、コンピューティングパワーをリモートで簡単に取り出すことができることにある。GPUコンピューティングについても、ローカルのアプリケーションを使っている感覚で、リモートのリソースを使えるようにすること、は明確な目標だ。NVIDIAは、この課題をどうしようとしているのか。
今年のPascal世代でさらに進化するNVIDIA GRID
NVIDIAはごく近い将来に、この問題を解決する。2016年のGPUでは、プリエンプションをサポートするからだ。「現在はプリエンプションをサポートしていないが、Pascalからはサポートする。カーネル実行途中でのスイッチが可能になる」とNVIDIAのMarc Hamilton氏(Solution Architecture & Engineering, VP, NVIDIA)は昨年(2015年)9月のGPU Technology Conference(GTC) Japan時に説明している。
2016年のNVIDIA GPUアーキテクチャのPascalからは、カーネルを実行途中で中断し、コンテキストをストアしてほかのカーネルをロード、その後、再び元のカーネルのコンテキストをリストアすることができるようになる。そのため、GRIDもPascal世代で次のステップへと進化、CUDAを自由に使うことができるようになると予測される。「複数のユーザーの仮想マシンが1個のPascal GPU上で走っていて」も、各仮想マシンでCUDAを走らせることができるようになるだろう。時間のかかるCUDAカーネルは、途中でプリエンプションにより切り替えが可能になり、他の仮想マシンに影響を及ぼさなくなる。
この段階になると、シミュレーションもGPUリソース活用が自由にできるようになり、GRIDの利用がさらに高度化する。より上位のユーザーにもGRIDが使いやすいものになる。
このように、NVIDIAのGRIDは継続的に進化しており、GRID 2.0移行の展望も見えている。GPU側のハードウェアの進化とともに、GPUの仮想化も進化して行く。GPUの仮想化の最終的なゴールは、CPUと同様の使い勝手を実現することだと見られる。
GRIDのその先のステップは、GPUの大きな難関である、マルチGPUにまたがる仮想化となる。現在のGPUは、CPUのように仮想化で、複数チップを1つのリソースとして扱うことができない。もちろん、分散化のフレームワークを使えばマルチGPUを使うことができるのだが、アプリケーションをそのままで、仮想化したマルチGPUに持って行くことができない。これについても、NVIDIAはNVLinkのような布石を打っており、将来的には対応する可能性がある。
いずれにせよ明確なことは、NVIDIAがGPUの仮想化を重視しており、ロードマップで革新して行くつもりでいることだ。GRID 3.0以降になると、GPUをコンピューティングリソースとして共有できるようになり、さらに一歩進む。
【仮想化道場】【GTC 2013レポート】NVIDIAが提供するクラウド/仮想環境向けのGPU「NVIDIA GRID」 - クラウド Watch
(部分引用)
NVIDIA GRIDは、GPUを、仮想化ソフトウェア技術環境からも利用できるようにする仕組みである。
3D CADやCAEなどの製造業のエンジニアが利用するアプリケーションを、ローカルのワークステーションではなく、データセンターに置かれたGPUで処理することを可能とする。
データをデータセンター内に置いたまま処理できるため、企業データのセキュリティを守る効果があるほか、世界各地の拠点でデータを共有したまま作業が進められるなどのメリットがある。
NVIDIAはこの秋に、同社の仮想GPU向けのソリューションであるNVIDIA GRIDの第2世代となるNVIDIA GRID 2.0を発表しており、同じ負荷であれば2倍の集約率、ないしは2倍の性能向上を実現していることが大きな特徴となる。
NVIDIA GRIDの説明をする前に、現代において企業、特にエンタープライズと呼ばれる大企業のIT環境がどのようになっているかを説明していく必要があるだろう。現在、エンタープライズのITでは「仮想化ソフトウェアと呼ばれる技術」が、クライアント(エンドユーザーが利用する端末)から、サーバー(データセンターに置かれて集中処理を担当するコンピュータ)まで普及しつつある。
特にクライアントでは、PCに代わって「VDI(Virtual Desktop Infrastructure)」と呼ばれるソリューションが利用されるようになってきた。具体的には、クライアントPCのストレージに物理的に置かれていたOSを、サーバーの仮想化ソフトウェア上に移動し、クライアントからは「リモートデスクトップ」という技術を利用し、ネットワーク経由で接続して利用するという仕組みだ。
このVDIは、すべてのデータ(OSやアプリケーションのファイル、各種ユーザーデータ)がサーバーにある仕組みなので、従来のノートPCやデスクトップPCを利用した場合と比べて、データ流出といったセキュリティ上の危険性が大幅に減少するのが特徴となる。
アクセスする端末はPCでなくてもよく、スマートフォン、タブレットなどのスマートデバイスや、「シンクライアント」と呼ばれるリモートデスクトップの機能を持つデバイスも利用できるので、高価なハイエンドPCを購入する必要がないことも特徴になる。
「以前のVDIはGPUの機能が用意されていなかったからだ」と述べ、GPUの機能をVDIで利用できなかったため、中途半端になっていたと説明した。
一般的なPCであろうが、エンジニアリングに利用されているワークステーションであろうが、現代のPCはCPUとGPUという2種類のプロセッサが内蔵されている。
CPUは主に一般的な処理を行ない、GPUはグラフィックス関連の処理を担当する。NVIDIA GRIDが登場する前のVDIでは、GPUの処理をCPUでエミュレーションして行なっていたため、性能が低かったり、3D CAD(3Dを利用したコンピュータシミュレーションのデザイン)やCAE(コンピュータシミュレーションを利用した設計)などのアプリケーションを利用するための機能が実装されていなかったりしていたのだ。
メイン氏は「エンドユーザーがデザイナーなのか、パワーユーザーなのか、ナレッジワーカーやタスクワーカーなのかによってニーズは異なっているが、いずれのユーザー層でもGPUは必須になりつつある。NVIDIAは“GRID”により、VDI環境でもGPUを利用する仕組みを提供する」と述べ、VDI環境でGPUが利用できる仕組みを提供することにより、VDI環境でもノートPCやデスクトップPCと同じように使える環境を実現すると説明した。
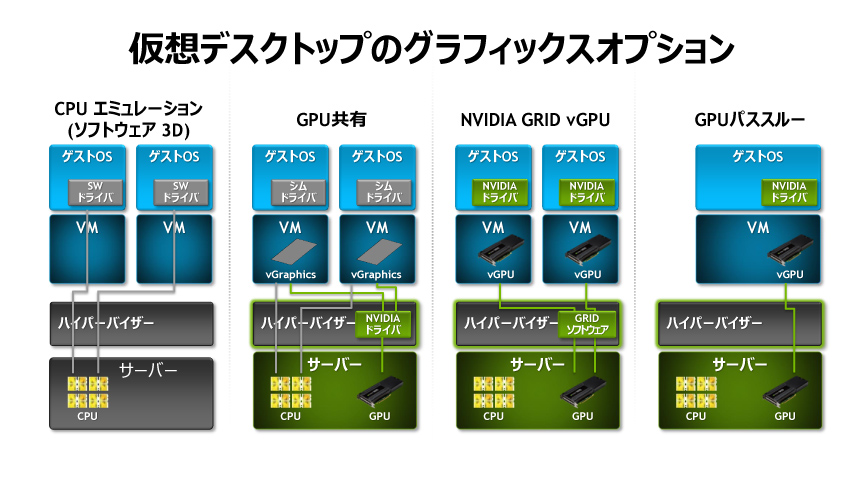
そうしたVDI環境でのGPU利用だが、その形態から「GPUパススルー」「シェアGPU」「vGPU」という3つの方式があるとした。
GPUパススルーというのは、ユーザーが利用しているOS(ゲストOSと呼ばれる)からGPUを利用する命令を来たときに、「ハイパーバイザー」と呼ばれるハードウェアを仮想化するソフトレイヤーが透過的にGPUに命令を伝達する仕組みだ。これにより性能は最もよく使えるが、ユーザーが利用するゲストOSとGPUは1対1で使わないといけないので、GPUの利用効率としてはGPUがローカルのPCにある場合とあまり変わらないことになる。
シェアGPUの場合にはハイパーバイザーの中にGPUのドライバが入っており、複数のゲストOSから出された要求を切り替えてGPUに伝えることができる。サーバーのGPUに対して複数のゲストOSを割り当てることができるため非常に効率がよい。しかし、この場合はゲストOSにインストールされているGPUのドライバは仮想的なドライバになってしまうので、プロフェッショナル向けの3D CADやCAEなどと互換性の観点で課題がある場合があった。
3つ目のvGPUの場合は、ハイパーバイザーの中で動作しているGRIDソフトウェアがvGPUという仮想GPUのモデルを作成し、ゲストOSに対してそれを仮想ハードウェアとして割り当てる。このため、ゲストOSでは一般的なGPUと同じデバイスドライバが利用できるため、3D CADやCAEのアプリケーションがそのまま利用できる。これらのアプリケーションから見ると、そこに本物のGPUがあるように認識されるからだ。また、ハイパーバイザー内のGRIDソフトウェアはデータセンターにある複数のGPUを使うことが可能になっているので、ハードウェアの有効活用もできるようになる。
メイン氏は「vGPUはGPUの利用効率が改善できるし、アプリケーションの互換性も改善している。これにより、異なるユースケースでもより高い性能要求にも応えることができる」と述べ、vGPUこそがGPU仮想化の本命であるとした。
日産では、日本以外にもあるグローバルなデザイン拠点間で、CAD/PDMデータに高速アクセスできる仕組みを導入する計画があったという。当初は複数の拠点、例えば日米欧それぞれに分散してデータを持つことが検討されたそうだが、それだと運用効率がわるいうえにコストも増える。さらには拠点間でのデータ同期を行なうことに対する不安などからその計画は破棄され、最終的にはNVIDIA GRIDを利用したVDIとvGPUの仕組みが導入されたのだという。
澤井氏は「現在、NVIDIA GRIDは多数のお客様に受け入れられており、航空機メーカー、自動車メーカーといった複数の製造業で採用されている」と述べ、自動車関連ではフォード、PSAグループ(プジョー・シトロエン)、ダラーラ(イタリアのレーシングカーコンストラクター)などで採用されていると説明した。
米国の病院のNVIDIA GRID導入事例では、医師は30分、看護婦は50分の業務効率化が可能になった
ノースカロライナ州立大学では、従来は図書館にあるワークステーションでしかCADなどを使えなかったが、NVIDIA GRIDの導入により、いつでもどこでも学生がCADなどを活用可能になった
建築会社のSSOEはグローバルな開発拠点で分散して処理できるようになった
NVIDIA GRIDの導入事例。フォードやダラーラ、PSAなどの自動車業界のメーカーも名を連ねている
そして、NVIDIA GRID 2.0について「GRID 2.0の特徴は、集約率が2倍ないしは性能が2倍。プラットフォームの密度が倍になり、さらにはサポートされるOSが2倍になる」と解説。澤井氏によれば、NVIDIA GRID 2.0ではGPUがNVIDIAの最新GPUとなる「Maxwell(マックスウェル)」世代に進化している。従来のNVIDIA GRID 1.0では「Kepler(ケプラー)」と呼ばれるやや古い世代のGPUが採用されていたが、これが最新世代のMaxwellベースになってことが性能向上の大きな要因になっているという。
さらに1つのGPUあたりのメモリが、GRID 1.0ではGPUあたり4GBだったのに対して、GRID 2.0では8GBへと強化されている。これらの理由により、純粋な性能としては2倍になっているという。集約数が倍というのは、1台のゲストOSあたりに同じ性能でよければ、1つのGPUに収納できるユーザー数が倍になっているということを意味している。
また、サポートされるOSが倍というのは、従来のGRID 1.0ではWindowsのみがゲストOSとしてサポートされていたが、GRID 2.0ではLinuxのサポートも追加されている。
澤井氏は「GRID 2.0はCITIRXやVMWareといった業界のリーダーからサポートされており、多くのOEMメーカーにより対応製品が出荷されている」と述べ、実際に同社の東京オフィスにあるGRID 1.0とGRID 2.0のサーバー上で展開されているVDIにネットワーク越しに接続して、処理能力が向上している様子などのデモを行なった。
NVIDIA、日産などに採用されたGPU仮想化「GRID 2.0」説明会 - Car Watch
Manufacturing Solutions - 日産自動車株式会社 - Citrix
北米時間2015年8月31日,NVIDIAは,米国サンフランシスコで開催された仮想化技術関連イベント「VMworld 2015 US」に合わせて,GPU仮想化ソリューション「NVIDIA GRID 2.0」を9月15日に提供開始すると発表した。
NVIDIA GRID 2.0は,第2世代Maxwellアーキテクチャを採用するGPUに対応したことと,1サーバーで対応できる最大ユーザー数が従来比で2倍の128人に増えたこと,ブレードサーバーに対応したこと,そして,Windowsに加えてLinuxに対応したことが特徴とされている。
NVIDIA GRIDといえば,クラウドゲームサービス「GRID Game Streaming Service」の基板技術でもあり,決してゲーマーと無縁なものではない。NVIDIA GRID 2.0の登場が,NVIDIAによるクラウドゲームサービスにどのような影響を与えるのかまでは明言されていないのだが,基板技術のバージョンアップに合わせて,GRID Game Streaming Serviceのシステムも更新される可能性は高いだろう。そうなれば,より快適なクラウドゲームサービスが利用できるようになるのではなかろうか。
VMware、Citrix、HP、DellなどがNVIDIA GRIDをエンタープライズ・ワークフローに提供
この技術を活用すれば、どのような機器でも、グラフィックスの要求性能がトップクラスのアプリケーションまで使うことが可能で、業界各社から幅広い支持を受けています。
NVIDIA GRID 2.0は、すでに10社前後のFortune 500企業がベータ版のトライアルを終了する段階に入っています。Cisco、Dell、HP、Lenovoといった大手サーバ・ベンダがGRIDソリューションを認証しており、利用できるサーバのモデルが125を数える状況になっていて今回は、新たにブレード・サーバでも使えるようになりました。
また、CitrixおよびVMwareとの緊密な協力により、業界をリードする仮想化プラットフォームでエンドユーザにリッチなグラフィックス体験を届けられるようにもなっています。
NVIDIA GRID 2.0は、エンタープライズ・ワークフローのグラフィックス仮想化において、そのパフォーマンスや効率、柔軟性をかつてないほど高めることができます。社員はどこにいても仕事ができるようになり、ファイルのダウンロードに時間を使う必要もなく、生産性が向上します。IT部門にとっては、リソースの割り振りを改善し、パワフルなアプリケーションを社員全員が利用できるようにすることができます。データの置き場所を個別のシステムではなく中央のサーバとすることで、セキュリティ面の改善も期待できます。
NVIDIAのCEO兼共同創立者、ジェンスン・フアン(Jen-Hsun Huang)は、次のように述べています。
「グラフィックス・インテンシブなワークフローをあらゆる機器にデータセンタから直接提供できるようにしようと、世界の業界リーダー各社がNVIDIA GRIDをこぞって採用しようとしています。NVIDIA GRIDテクノロジがあれば、どこにいても、どのような機器を使っていても、最高の仕事をすることが可能なのです。これこそ、エンタープライズ・コンピューティングの未来だと言えます」
エンタープライズ・ワークフローをデータセンタから仮想化するというのは、いままでパフォーマンスが悪すぎる、ユーザ体験が劣化する、サポートされているサーバやアプリケーションに制限があるなどの問題から不可能な状況にありました。
NVIDIA GRID 2.0でGPUをデータセンタに統合すれば、以下のように、これらの障害がすべてクリアされます。
●ユーザ密度倍増――NVIDIA GRID 2.0はサーバあたり128ユーザまで可能と、昨年発表された旧バージョンに比べてユーザ密度が倍増しています。この結果、スケールアップのコスト効率が改善され、ユーザひとりあたりの費用を抑え、多くの社員にサービスを提供することが可能になりました。
●アプリケーション・パフォーマンス倍増――NVIDIA GRID 2.0は高い評価を得ているNVIDIA Maxwell GPUアーキテクチャの最新バージョンを使用しています。その結果、アプリケーション・パフォーマンスが倍増し、多くのネイティブ・クライアントを凌駕するレベルに達しました。
●ブレード・サーバのサポート――いままではラック・サーバが必要でしたが、大手ブレード・サーバ・プロバイダのブレード・サーバでもGRID対応の仮想デスクトップを走らせられるようになりました。
●Linuxのサポート――NVIDIA GRID 2.0はWindowsのみというオペレーティングシステムの制限がなくなり、Linuxのアプリケーションやワークフローを活用しているエンタープライズ各社にも高速化グラフィックスによる仮想化の恩恵を提供できるようになりました。
さまざまな業界の企業10社前後がNVIDIA GRID 2.0のパイロット試験に参加し、ユーザの生産性やIT効率、セキュリティ向上などの面でどのようなメリットが得られたのかを報告していただいています。
Textron社のシニア・アーキテクト兼ITインフラストラクチャ・マネジャーのフレッド・デバール(Fred Devoir)氏は、次のように述べています。
「NVIDIA GRIDのおかげで、エンジニアリング設計や解析の幅広いアプリケーションが利用できるようになりました。設計データの利用に無駄がなくなり、遠い場所にある製造施設にデータの写しを送る必要もなくなり、生産性が高まりました。最新の2.0では、ひとつのGPUを同時に利用できるユーザの数が倍増したり、ビデオ・メモリの最大容量拡大によってパフォーマンスを犠牲にすることなく同時並行に利用できるアプリケーションの数が増えたりといったメリットが得られました」
VMwareのエンドユーザ・コンピューティング担当上級副社長兼ジェネラルマネジャー、サンジェイ・プーネン(Sanjay Poonen)氏は、次のように述べています。
「NVIDIA GRID 2.0とVMware Horizonの組み合わせは、仮想デスクトップの全社展開で未来を担うイノベーションとなるでしょう。VMwareのエンドユーザ・コンピューティング・ソリューションは、かつてない形で職場の力を高めることが可能な、使いやすく、かつ、安全なテクノロジとして力を発揮してきました。VMwareでは、NVIDIAとの緊密な協力を通じて、今後も、パワフルな機能を顧客にお届けしていきたいと考えています。これはまた、当社がデスクトップ仮想化市場でシェアを広げている一因でもあると思います」
Citrix社でプロダクト・マーケティング、Windowsアプリ・デリバリーを担当するバイスプレジデント、カルバン・シュー(Calvin Hsu)氏は、次のように述べています。
「2013年、CitrixとNVIDIAは共同で初となるvGPUソリューションをリリースし、複数の仮想デスクトップでひとつのGPUを共有し、妥協のない体験をスケールアップが簡単な形で提供できるようにしました。今回、提供するCitrixのXenAppおよびXenDesktopのアプリとデスクトップにNVIDIA GRID 2.0という組み合わせなら、どのようなデバイスでもリッチなアプリケーションが使えるというメリットをかつてないほど多くのユーザに活用していただけるでしょう」
Esri社でパフォーマンス・エンジニアリングを統括するジョン・メザ(John Meza)氏は、次のように述べています。
「ArcGIS ProはGRIDを活用してバーチャル環境で優れたユーザ体験を提供する当社の最新デスクトップ製品で、Esri社にとってとても重要な製品です。これを使えば、物理的環境でも仮想環境でも、好みの環境で作業を続けることが可能になります」
HP BladeSystemの副社長兼ジェネラルマネジャー、ニール・マクドナルド(Neil MacDonald)氏は、次のように述べています。
「GRID 2.0の登場により、当社は、パワフルかつセキュアで、信頼性の高いブレード・サーバ構成を顧客に提供できるようになりました。高速化グラフィックスを活用するワークフローをすべて仮想化する際の選択肢が増えたのです。GRIDテクノロジのおかげで、HPは、顧客各社にこれ以上はないというほどのユーザ数まで容易にスケーリングしていただけるよう、現在の市場で最高密度を誇る仮想グラフィックス製品を提供できるようになりました」
Dellのサーバ・ソリューション担当エグゼクティブ・ディレクタ、ブライアン・ペイン(Brian Payne)氏は、次のように述べています。
「Dellは、顧客各社が直面するIT課題に対処できるようにと、昔から、革新的なシミュレーションを他社に先駆けて市場に投入してきました。今回も、業界の先陣を切り、エンタープライズGPUソリューションによって当社サーバ・エコシステムの生産性やセキュリティ、効率を向上できるように、NVIDIAと緊密に協力してきました」
GPU仮想化ソリューション「NVIDIA GRID 2.0」は、基本的にはGPU対応アプリケーションを使う企業や学術機関向けのソリューションであり,ゲーマーが直接利用するものではない。
GRID 2.0は基本的に,仮想マシン環境を使った「Virtual Desktop Infrastructure」(仮想デスクトップ基盤,以下,VDI)上で利用するものだ。ココでいうVDIとは,個々のユーザーが利用するアプリケーションを,すべてサーバー側で実行する仮想マシン上で管理するものだ。各ユーザーはPCやシンクライアントなどを利用して,ネットワーク経由でサーバーに接続して,仮想マシンを利用する。
余談だが,NVIDIAのGPU仮想化ソリューションは,システムインテグレータがハードウェアとともに企業ユーザーに販売する方式のほか,Amazon.comが展開しているように,クラウドサービス事業者がサービスとして提供する方式でも提供されている。
そのため,NVIDIAが直接に企業ユーザーにVDIサービスを提供するわけではない。
これまでのVDIは,GPUをサポートしておらず,ソフトウェアで仮想マシンのハードウェアをエミュレーションしていた。そのためグラフィックス性能は非常に低く,GPUを正確に再現することもできなかったので,GPUを利用するアプリケーション――たとえば業務用のCG制作アプリケーションやCADアプリケーションなど――が利用できなかったという。
デザイナーやパワーユーザーが利用するアプリケーションの多くが,GPUを事実上必須としているとMain氏。また,医療現場などでは非常に高解像度のグラフィックスが使われるため,ここでもGPUが必要になるという
だが,NVIDIAの仮想GPU技術を使えば,サーバー側に装備されたGPU(以下,物理GPU)を仮想化し,各ユーザー側の仮想マシンでGPU対応アプリケーションを利用できるようになる。また,1台の物理GPUを複数の仮想マシンに振り分けることで,複数のユーザーによる処理を同時にこなすことも可能だ。
これによって,CG制作アプリケーションやCADアプリケーション,あるいはCUDAによるGPU演算を使ったアプリケーションを同時に複数のユーザーが利用できるようになるわけだ。
仮想マシンにおけるGPUの仮想化には,いくつかのパターンがある。最も一般的なのは,ホストOS側でのソフトウェアエミュレーション(CPUエミュレーション)だが,性能や互換性で問題がある。NVIDIAのGRIDサービス(※図の右から2つめ)は,物理GPUの性能を効率よく仮想マシン側で利用できるそうだ
NVIDIAによれば,前世代の「GRID 1.0」と比べて,GRID 2.0はおよそ2倍の性能があるという。対応GPUは,第2世代Maxwellアーキテクチャの「Tesla M60」,または「Tesla M6」となり,GPU 1基あたりのメモリ容量は,従来の4GBから8GBに倍増。これにより,同時利用ユーザー数は従来比で2倍の32人に増加し,ユーザー数が同一ならば,ユーザーあたりのグラフックス性能を2倍にすることも可能となったそうだ。
GRID 1.0と2.0の性能を比較したグラフ。「集約率」とは,物理GPU 1基でサポート可能なVM数=同時利用ユーザー数のこと。GRID 2.0では,最大32ユーザー(32VM)まで同時に処理でき,16ユーザーまでのGRID 1.0と比べて倍のユーザー数をサポートしている
そのほかにも,GRID 2.0ではLinux用の仮想GPUドライバが提供されるようになり,仮想マシン側のゲストOSとして,WindowsだけでなくLinuxも利用可能になったことも特徴であるとのことだった。
さて,GRID 2.0が登場したことにより,同じGRIDの名を冠するGRID Game Streaming Serviceのほうも,GRID 2.0ベースにアップデートされたのかどうかが,ゲーマーとしては気になるところかもしれない。だが,説明会でGRIDの導入事例を紹介したエンタープライズソリューションプロダクト事業部の澤井理紀氏や,テクニカルエンジニアの矢戸知得氏に確認してみても,GRID Game Streaming ServiceがGRID 2.0ベースになったのかどうかは,不明であるとのことだった。
ただ,最近は北米で,Androidベースの据え置き型ゲーム機である「SHIELD」が好調なこともあってか,ユーザー数が急激に増加したことにより,NVIDIAのクラウドゲームサービスである「GRID Game Streaming Service」がアクセス人数の上限に達したこともあったそうだ。
GRID Game Streaming ServiceもGRID 2.0ベースのシステムに移行すれば,より多くのユーザーが同時にゲームをプレイすることも可能になるはずで,それはゲーマーにとってもメリットをもたらすことになるだろう。
(部分引用)
メイン氏は、「かつては会社が保有する端末があり、オフィスでのみ仕事が可能で、データもローカルに存在していたが、そういった世界は今や存在しない」と述べ、従業員は顧客のオフィスや自宅などリモートオフィスで業務が可能な環境を求めているとした。またITというのは、ユーザーがどこに居ようと最大の生産性を発揮できるように、必要なソフトウェアを提供するなどサポートできなくてはいけないと述べた。
またビジネスユーザの生成しているデータ量は、個々のファイル単体の大きさの増大もあり、爆発的に増加しており、世界で1年間に3.5ZB、1TB HDD換算で35億個に相当するビジネスデータが生成されているという。
これらの膨大なデータはどこからでもアクセス可能であるとともに、セキュアな状態で管理する必要がある。
ユーザーはスマートフォンやタブレット、MacBookといった、使い慣れた端末で業務を行ないたいと思っており、どのような端末でも、あらゆるアプリケーションの使用をサポートできる環境を提供することで、生産性の障害を排除しビジネスの加速に繋がるとした。
従来の業務スタイルは機能しない
働く場所はオフィスとは限らない
膨大なデータとセキュリティ
あらゆるデバイスの業務利用
従業員の生産性を阻害する障壁を取り除く
仮想デスクトップインフラストラクチャ(VDI)
そういった環境を提供するための解決策として生まれたのが、「仮想デスクトップインフラストラクチャ(VDI)」と呼ばれるコンピューティングモデルだ。
しかし、従来のVDIは、今やPCのコアコンポーネントであるGPUへのアクセスが欠如しており、GPUを利用する用途には対応できなかった。そのため、CPUによるGPUのソフトウェアエミュレーションを行なうことで解決を試みたものの、性能が低く、アプリケーションとの互換性も低かったため、ユーザーが従来利用していた環境から劣化したものしか提供できないか、あるいはアプリケーションの仮想化自体ができない場合もあったという。その結果としてVDIそのものがニッチソリューションとなってしまったと述べた。
メイン氏は、GPUを使用したコンピューティングを必要とするユーザーの区分を挙げ、GPUへの要件が高い順にデザイナー、パワーユーザー、ナレッジワーカーの4つを提示した。
デザイナーはAutodeskやSolidWorks、PCTといったソフトウェアを使用して3Dエンジニアリングや設計を行なっている層で、パワーユーザーは、前述のAutodeskのデータ閲覧や、PLMソフトウェアのTeamCenterの利用、またAdobe製品などを利用したアニメやデザイン設計を行なっている層、ナレッジワーカーは、3DアプリケーションやFlash/HTML5アプリケーションを利用している層をそれぞれ指す。
またこれらの層に限らず、よりGPUの要件が低いタスクワーカーの場合でも、Office製品群やWindows OSを利用していれば、GPUでアクセラレーションが行なわれている。
これらのGPUに対して高い需要を持っている層に対し、従来のVDIはその要件を満たした環境を提供できなかったとした。
メイン氏は、NVIDIAが提供するGPU仮想化ソリューション「GRID」によって、デザイナーからタスクワーカーまで、生産性、携帯性、安全性を含む全需要をカバーできるようになったと述べた。
NVIDIA GRIDテクノロジーは、サーバーの中に存在するGPUを仮想化し、複数のVDIインスタンスで共有可能とするもの。メイン氏は「これによって、あらゆるリモート端末に対してデータセンターから“真のPC体験”を提供可能となった」とした。
また、従来は各ローカルマシンが保持していたデータを、サーバーに集約することでセキュアに管理可能となった。
ユーザー目線からの利点としては、シンクライアントやChromebook、Apple製品、スマートフォンなど、あらゆる端末、場所を問わず、自身のワークスタイルに沿った形で仕事が可能となることで、生産性の向上に繋がるとした。
続いてメイン氏は、GRIDとそのほかの仮想デスクトップで提供されているグラフィックスオプションとの解説を行なった。
初期のVDIでは、3Dアプリケーションを有効化する唯一の手段がソフトウェアによるGPUのCPUエミュレーションで、このようなソフトウェアでエミュレートされたGPUは、前述の通り、アプリケーションの互換性が低く、また複数ユーザーが同時利用した場合の性能低下が問題となっていたという。
そういった互換性、拡張性の問題を解決するため、NVIDIAではハイパーバイザーと連携し、「GPUパススルー」を実現した。これはアプリケーションの互換性を解決し、高い性能を達成したが、1インスタンスにつき1GPUを割り当てるため、サーバーに搭載可能なGPUの台数に限りがある以上、サーバーごとユーザー密度が低くなってしまう。
ユーザー密度問題の対策として、複数のインスタンスでGPUを共有できる「GPU共有テクノロジー」が発表されたが、高い性能は実現できたものの、CPUエミュレーションと同様にアプリケーションの互換性が低いままだった。
それらに対し、2013年に発表した「GRID vGPUテクノロジー」では、アプリケーションの互換性など、GPUパススルーの機能や性能を実現しつつ、ユーザー密度の問題も解決しているという。
仮想環境におけるグラフィックス性能とユーザー層毎の要件をマッピングしてみると、タスクワーカーはソフトウェアエミュレーションでカバーはされていたが性能が低く、対しデザイナーはGPUパススルーによってカバーされていたが、拡張性の問題を抱えている。こういったギャップを埋めるべくGPU共有が登場したが、全ての需要をカバーするには至らなかった。
GRID vGPUによって、高い性能と互換性を持ったVDIインスタンスをデスクトップへ提供できるようになったという。
まず国外の導入事例として、米ミシガンで医療事業を展開するMetroHealthでの例を挙げ、同社ではGRID導入以前からVDI環境を導入していたが、GRIDへ切り替えたことにより、1日あたり医師で30分、看護師で50分を短縮でき、生産性の向上を達成したという。
2点目はノースカロライナ大学での導入事例で、同大学ではSolidWorksやAutoCADなどのCADソフトウェアをVDI環境で提供することで、従来図書館に設置していた端末からしか利用できなかったそれらのソフトを、ネット環境さえあればどこからでもアクセスできるようにしたという。
3点目は建築管理会社のSSOEで、7カ国29オフィスに分散したエンジニアが、建築データを利用する際に、従来は巨大なデータをローカルへ保存する必要があり、時間がかかる上にデータが分散しセキュリティ面のリスクを抱えていたが、GRIDを使用したVDI環境の導入で2つの問題を解決しているとした。
国内でも、日産自動車や、TOTO、造船会社のマリンユナイテッドなど、CADなどの3Dアプリケーションを使用する企業で導入されているという。
澤井氏は、Windows 10や、Vulkanなど新しいグラフィックスAPIなどが登場しており、よりグラフィックスへの要求が高まっているとし、このニーズに応えるために数十億ドルを研究開発に投資していると述べた。
まず集約率については、GRID 1.0で16台、GRID 2.0で32台の仮想マシンを動作させた、同じ仕様で集約が異なるサーバーを用意し、ベンチマークソフトSPECviewperfのスコアを比較したところ、同等のスコアを記録したという。また実使用環境を想定し、地理情報システムアプリケーションのArcGISの動作を比較した場合でも、描画時間はほぼ同等を実現しているという。
また1インスタンスに割り当てられるフレームバッファ容量を8GBまで割り当て可能となり、より高い性能を必要とするユースケースでも対応できるようになった。メイン氏によると、8GBを割り当てた状態ではインスタンス数に制限が発生するため、集約率は低下してしまうが、この場合ではCUDAの利用も可能となるという。
プラットフォームについては、従来から対応していたラックサーバーだけでなくブレードサーバーをサポート。OSについても、新たにLinuxをサポートし、選択肢が2つ(2倍)に増えた。
澤井氏によれば、今回のGRID 2.0での性能と集約率の向上は、対応GPUが更新されたことが大きいという。GRID 2.0はMaxwellアーキテクチャを採用する「TESLA M60」、「TESLA M6」が対応している。
ライセンス形態については、今までの導入事例ではオンプレミスのサーバーへ導入されており、その場合は使用用途やサポート内容よって、いくつかのプランから選択する形となる。
しかし9月にMicrosoftがAzureでのGRID 2.0提供を発表したように、クラウドでのGRID提供の場合には、別途支払うのではなく、クラウドサーバーの利用料金と合算した形で提供されるのではとのことだった。